On 15 May 2025, Phoronix published an article comparing the performance of several Linux distributions on a Framework Laptop 13. Out of curiosity we are going to check a pair of things with a similar evaluation. In this case the hardware being put to test is a ThinkPad E14 Gen 7, with an AMD Ryzen 5 220 CPU and 32 GB of RAM.
Linux distributions
| Kernel | File system | |
|---|---|---|
| Arch Linux | 6.18.6-arch1-1 (x86_64) | ext4 |
| CachyOS | 6.18.7-2-cachyos (x86_64) | btrfs |
| CachyOS - ext4 | 6.18.8-3-cachyos (x86_64) | ext4 |
| Debian 13 | 6.12.63+deb13-amd64 (x86_64) | ext4 |
| Debian 13 - 6.17.13 | 6.17.13+deb13-amd64 (x86_64) | ext4 |
| Fedora 43 | 6.18.6-200.fc43.x86_64 (x86_64) | btrfs |
| Gentoo Linux | 6.12.63-gentoo-dist (x86_64) | xfs |
| Gentoo Linux - 6.18.7 | 6.18.7-gentoo-gentoo-dist (x86_64) | xfs |
| Ubuntu 25.10 | 6.17.0-8-generic (x86_64) | ext4 |
Here there are six distinct Linux distributions, all installed with their supposedly default settings.
For instance, Arch Linux was installed on an ext4 partition, an example in the installation guide was pointing toward that choice. Instead Gentoo's recommended filesystem has always been xfs:
XFS is the recommended all-purpose, all-platform filesystem.
The partition was mounted with the noatime flag. The compilation flags were the same seen in the handbook:
COMMON_FLAGS="-march=native -O2 -pipe"
CachyOS and Fedora were both installed on btrfs partitions, with CachyOS utilizing the noatime flag. CachyOS, Debian and Gentoo were also tested with an important change to their default installations: CachyOS on an ext4 partition, Debian and Gentoo with a more recent kernel.
Phoronix Test Suite
The majority of tests were executed through the Phoronix Test Suite 10.8.4. The benchmarks were chosen from the most popular ones, as provided by the list-recommended-tests command. A subset of these tests and their options is shown below, for the complete results check:
OpenBenchmarking.org - uploaded results
LevelDB
Test type: System
Gentoo is notably slow here, this could be an edge case where xfs is penalized. Other tests show a less surprising performance pattern.
SQLite
Test type: Disk
Btrfs underperforms in this test. This was expected, see this other Phoronix article:
Bcachefs, Btrfs, EXT4, F2FS & XFS File-System Performance On Linux 6.15
SuperTuxKart
Test type: Graphics
Phoronix Test Suite recorded a screen resolution of 3072x1920 for Debian and Ubuntu, while the actual hardware resolution was 1920x1200. This could explain the sluggish performance in this benchmark.
The situation is the same with Vulkan. While the FPS doubled, shadows and other effects were missing in this version of the test.
Unvanquished
Test type: Graphics
Unvanquished runs flawlessly on Debian and Ubuntu and, interestingly, Arch Linux is faster than CachyOS.
MBW
Test type: Memory
Timed Linux Kernel Compilation
Test type: Processor
CachyOS and Debian were the fastest while Gentoo was severely beaten at its own game.
BRL-CAD
Test type: System
Geometric mean
Here is the geometric mean of all the results, including Waifu2x-NCNN Vulkan, 7-Zip Compression and Blender.
However, excluding LevelDB (Fill Sync), SQLite, and SuperTuxKart, we get a more balanced and perhaps fairer representation.
CachyOS is the fastest, followed by Debian.
PassMark
Another bunch of tests were executed with PassMark PerformanceTest Linux (11.0.1004).
| CPU | Memory | |
|---|---|---|
| Arch Linux | 18598 | 3185 |
| CachyOS | 18767 | 2618 |
| CachyOS - ext4 | 18707 | 3298 |
| Debian 13 | 18805 | 3319 |
| Debian 13 - 6.17.13 | 18803 | 3315 |
| Fedora 43 | 18617 | 3240 |
| Gentoo Linux | 18774 | 3263 |
| Gentoo Linux - 6.18.7 | 18807 | 3312 |
| Ubuntu 25.10 | 18614 | 3266 |
In this case Debian and Gentoo Linux are the fastest, while Arch Linux is the slowest. CachyOS (on btrfs) encountered an issue during the memory benchmark:
Memory Mark: 2618 Database Operations 5781 Thousand Operations/s Memory Read Cached 37405 MB/s Memory Read Uncached 36773 MB/s Memory Write 28453 MB/s Available RAM 3560 Megabytes Memory Latency 58 Nanoseconds Memory Threaded 57572 MB/s
Memory Mark was reporting only 3560 MB of available RAM. This should be a one-time anomaly with PassMark.
Geekbench
Last, there is Geekbench 6.5.0.
| Single-Core | Multi-Core | |
|---|---|---|
| Arch Linux | 2715 | 9864 |
| CachyOS | 2718 | 9815 |
| Debian 13 | 2715 | 9881 |
| Fedora 43 | 2618 | 9464 |
| Gentoo Linux | 2594 | 9430 |
| Ubuntu 25.10 | 2588 | 9422 |
Geekbench shows results in line with the Phoronix Test Suite.
Conclusion
Overall, what Phoronix shows in its article is confirmed here: CachyOS appears to be the most performant Linux distribution, followed by Debian. While Arch and Gentoo offer great opportunities for customization, they are behind, unless you invest more time in optimization. There is no substantial difference between a 6.12 or a 6.18 kernel in these tests. Many of the benchmarks out there have quirks that needs to be taken into account when interpreting the results.
If you have been using Hibernate for some time you should know that the best way to map a one-to-many relationship is through a bidirectional @OneToMany association where the mappedBy attribute is set. It is well explained in this article:
The best way to map a @OneToMany relationship with JPA and Hibernate
See also the Hibernate ORM User Guide.
Now, in honour of Saint Thomas, we are going to verify ourselves if that's true. Furthermore we will investigate what happens when we add the @OrderColumn annotation.
Sample project
The sample project is based on Hibernate 5.4.1.Final and Postgres. There are two tables, master and slave, with auto-incrementing primary keys. The slave table has a foreign key on id_master and a column named index which will be used later with @OrderColumn.
CREATE TABLE master
(
id serial NOT NULL,
description text,
CONSTRAINT master_pkey PRIMARY KEY (id)
)
CREATE TABLE slave
(
id serial NOT NULL,
description text,
id_master integer,
index integer,
CONSTRAINT slave_pkey PRIMARY KEY (id),
CONSTRAINT slave_master_fk FOREIGN KEY (id_master)
REFERENCES master (id)
)
Unidirectional association
First case. We have two entities, Master and Slave. Master has a list of slaves mapped with @OneToMany and @JoinColumn annotations, the mappedBy attribute is not used. Slave has no association towards Master.
@Entity(name = "MasterNoOrderUni")
@Table(name = "master")
public class Master
{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id = 0;
private String description = "";
@OneToMany(
cascade = CascadeType.ALL,
orphanRemoval = true)
@JoinColumn(name = "id_master")
private List<Slave> slaves = null;
// ...
public void addSlave(String description)
{
Slave slave = new Slave(this, description);
slaves.add(slave);
}
// ...
}
@Entity(name = "SlaveNoOrderUni")
@Table(name = "slave")
public class Slave
{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id = 0;
private String description = "";
// ...
}
Then, this is the code to persist a new Master and three Slave instances. I hope you will not be offended by what you are going to read, JPA providers are hellish tools.
app.ms.noOrderColumn.unidirectional.Master master =
new app.ms.noOrderColumn.unidirectional.Master("Devil");
master.addSlave("Devil's slave A");
master.addSlave("Devil's slave B");
master.addSlave("Devil's slave C");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.persist(master);
em.getTransaction().commit();
em.close();
Revised console output follows.
insert into master
(description)
values
('Devil')
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 13
insert into slave
(description)
values
('Devil''s slave A')
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 37
insert into slave
(description)
values
('Devil''s slave B')
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 38
insert into slave
(description)
values
('Devil''s slave C')
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 39
update slave set
id_master=13
where
id=37
update slave set
id_master=13
where
id=38
update slave set
id_master=13
where
id=39
Clearly the three update statements could have been avoided. The insert statements are executed on the persist instruction, the update statements are executed on the commit instruction. It is all implementation-related.
Bidirectional association
Second case. A @ManyToOne and a @JoinColumn have been added to Slave, so now a bidirectional association is in place.
This is not a bidirectional association in JPA terms (see SR 338: Java Persistence 2.2 - page 44, 2.9 Entity Relationship) but in this context we need to make a distinction, that is: Bidirectional association vs Bidirectional association with mappedBy.
@Entity(name = "MasterNoOrderBi")
@Table(name = "master")
public class Master
{
// ...
@OneToMany(
cascade = CascadeType.ALL,
orphanRemoval = true)
@JoinColumn(name = "id_master")
private List<Slave> slaves = null;
// ...
}
@Entity(name = "SlaveNoOrderBi")
@Table(name = "slave")
public class Slave
{
// ...
@ManyToOne
@JoinColumn(name = "id_master")
private Master master = null;
// ...
}
Here there is only a German difference.
app.ms.orderColumn.bidirectional.Master master =
new app.ms.orderColumn.bidirectional.Master("Teufel");
master.addSlave("Teufel's slave A");
master.addSlave("Teufel's slave B");
master.addSlave("Teufel's slave C");
// ...
The output.
insert into master
(description)
values
('Teufel')
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 14
insert into slave
(description, id_master)
values
('Teufel''s slave A', 14)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 40
insert into slave
(description, id_master)
values
('Teufel''s slave B', 14)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 41
insert into slave
(description, id_master)
values
('Teufel''s slave C', 14)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 42
update slave set
id_master=14
where
id=40
update slave set
id_master=14
where
id=41
update slave set
id_master=14
where
id=42
We still have inefficiency. d_master is set immediately with the insert statements but the same identical result could have been obtained in the previous case by setting @JoinColumn with nullable to false.
@JoinColumn(name = "id_master", nullable = false)
So, effectively, we can consider this case like a unidirectional association.
Bidirectional association with mappedBy
Third case. This time Master has a @OneToMany annotation and the mappedBy attribute is there in all its glory, moreover no @JoinColumn is present because the field that owns the relationship is in Slave.
@Entity(name = "MasterNoOrderBiMappedBy")
@Table(name = "master")
public class Master
{
// ...
@OneToMany(
mappedBy = "master",
cascade = CascadeType.ALL,
orphanRemoval = true)
private List<Slave> slaves = null;
// ...
}
@Entity(name = "SlaveNoOrderBiMappedBy")
@Table(name = "slave")
public class Slave
{
// ...
@ManyToOne
@JoinColumn(name = "id_master")
private Master master = null;
// ...
}
Here there is only a Spanish difference.
app.ms.orderColumn.bidirectional.mappedBy.Master master =
new app.ms.orderColumn.bidirectional.mappedBy.Master("Diablo");
master.addSlave("Diablo's slave A");
master.addSlave("Diablo's slave B");
master.addSlave("Diablo's slave C");
// ...
And the result is shorter than before.
insert into master
(description)
values
('Diablo')
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 15
insert into slave
(description, id_master)
values
('Diablo''s slave A', 15)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 43
insert into slave
(description, id_master)
values
('Diablo''s slave B', 15)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 44
insert into slave
(description, id_master)
values
('Diablo''s slave C', 15)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 45
The three update statements previously seen have disappeared, this is what we would have expected from the start. It is confirmed, the bidirectional association with mappedBy is the best way to map a @OneToMany relationship (with Hibernate, for now).
@OrderColumn
But what happens when @OrderColumn is used to maintain order between the slaves?
Several past Hibernate versions were having problems with @OrderColumn (or the deprecated @IndexColumn) when it was combined with @OneToMany and mappedBy (e.g., see here, here and here).
Now we have to put the finger in this wound also, adding @OrderColumn to the previous mappings.
// ...
// Unidirectional
@OneToMany(
cascade = CascadeType.ALL,
orphanRemoval = true)
@JoinColumn(name = "id_master")
@OrderColumn(name = "index", nullable = false)
private List<Slave> slaves = null;
// ...
// Bidirectional with mappedBy
@OneToMany(
mappedBy = "master",
cascade = CascadeType.ALL,
orphanRemoval = true)
@OrderColumn(name = "index", nullable = false)
private List<Slave> slaves = null;
// ...
Output for the unidirectional association.
/*
Unidirectional
*/
insert into master
(description)
values
('Devil')
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 16
insert into slave
(description)
values
('Devil''s slave A', 16)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 46
insert into slave
(description, id_master)
values
('Devil''s slave B', 16)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 47
insert into slave
(description, id_master)
values
('Devil''s slave C', 16)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 48
update slave set
id_master=16,
index=0
where
id=46
update slave set
id_master=16,
index=1
where
id=47
update slave set
id_master=16,
index=2
where
id=47
Output for the bidirectional association with mappedBy.
/*
Bidirectional with mappedBy
*/
insert into master
(description)
values
(Diablo)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 18
insert into slave
(description, id_master)
values
('Diablo''s slave A', 18)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 52
insert into slave
(description, id_master)
values
('Diablo''s slave B', 18)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 53
insert into slave
(description, id_master)
values
('Diablo''s slave C', 18)
-- DEBUG o.h.id.IdentifierGeneratorHelper - Natively generated identity: 54
update slave set
index=0
where
id=52
update slave set
index=1
where
id=53
update slave set
index=2
where
id=54
It is a step back. When @OrderColumn enters the scene even a bidirectional association with mappedBy becomes plagued by those ugly update statements. Does it means that the two types of association are now equivalent? Not really. Let's consider another situation.
// ...
app.ms.orderColumn.unidirectional.Master master =
em.find(app.ms.orderColumn.unidirectional.Master.class, 16);
master.removeSlave("Devil's slave B");
// ...
app.ms.orderColumn.bidirectional.mappedBy.Master master =
em.find(app.ms.orderColumn.bidirectional.mappedBy.Master.class, 18);
master.removeSlave("Diablo's slave B");
// ...
We are putting an end to the sufferings of slaves B.
/*
Unidirectional, remove B
*/
update slave set
id_master=null,
index=null
where
id_master=16
and id=48
update slave set
id_master=null,
index=null
where
id_master=16
and id=47
update slave set
id_master=16,
index=1
where
id=48
delete from slave
where
id=47
The first two updates are useless. Hibernate is setting the id_master and index columns to null for all those elements that it has effectively to update or delete. It is applying a sort of punishment.
/*
Bidirectional with mappedBy, remove B
*/
update slave set
index=0
where
id=52
update slave set
index=1
where
id=54
delete from slave
where
id=53
The first update is useless. Hibernate is updating the index column for all the remaining elements.
At first sight it could be said that the bidirectional association with mappedBy is still the best because there are less update statements, but what would have happened removing slave C instead of B?
/*
Unidirectional, remove C
*/
update slave set
id_master=null,
index=null
where
id_master=16
and id=48
delete from slave
where
id=48
/*
Bidirectional with mappedBy, remove C
*/
update slave set
index=0
where
id=52
update slave set
index=1
where
id=53
delete from slave
where
id=54
Conclusion
The best way to map a @OneToMany relationship with Hibernate is through a bidirectional association (with mappedBy), but this is true if @OrderColumn is not being used. When @OrderColumn is specified then the number of elements involved and the operations performed must be considered. Other JPA providers (precisely EclipseLink and OpenJPA) are doing better in some of the cases analyzed here, so let's keep an eye on Hibernate 6 or 666.
RogueFlash, various implementations of a simplistic flashcard software to explore a range of technologies.
Inspired by TodoMVC and Kent Beck.(2023) RogueFlashVueQs
Single-page / Electron application.
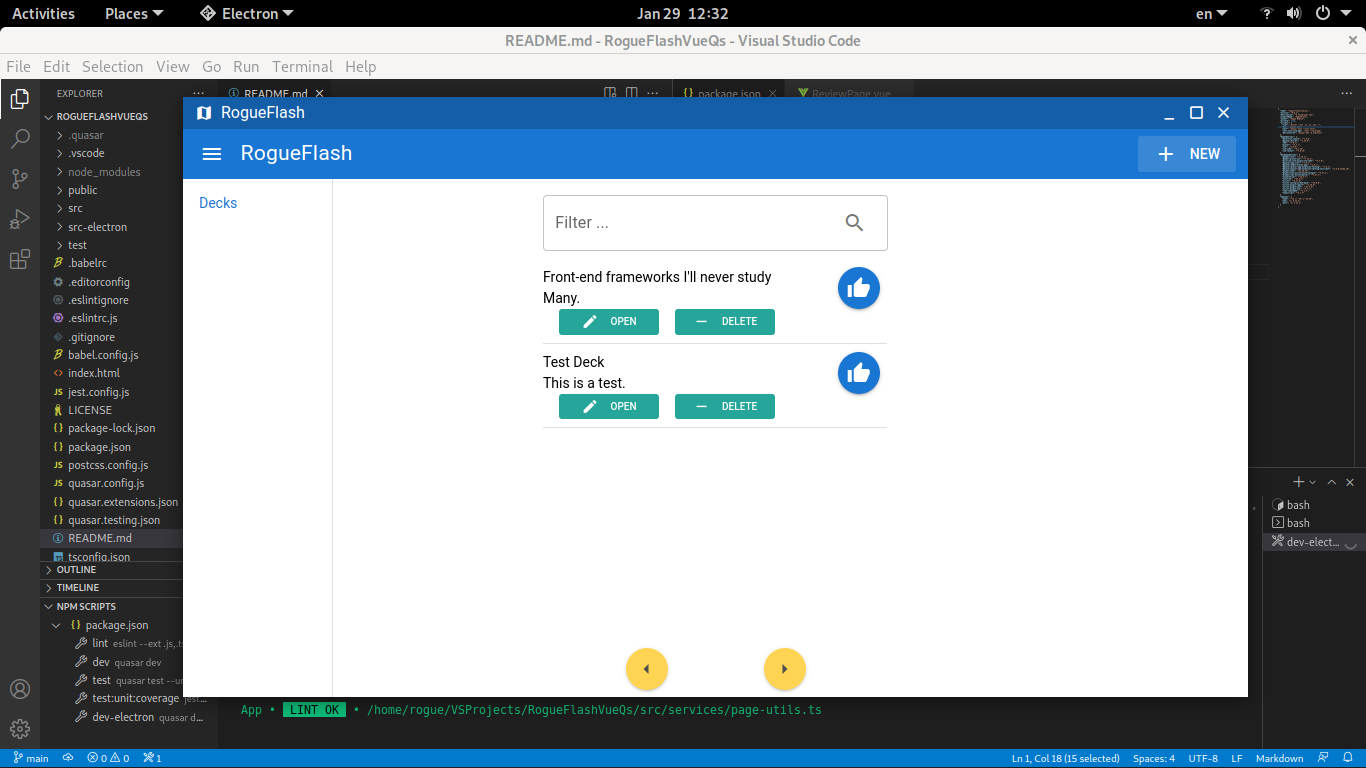
| Electron | 22.0.3 |
| ESLint | 8.17.0 |
| idb | 7.0.1 |
| Jest | 26.6.3 |
| Quasar Framework | 2.7.1 |
| TypeScript | 4.7.3 |
| Visual Studio Code | 1.74.3 |
| Vue I18n | 9.1.10 |
| Vue Router | 4.0.15 |
| Vue.js | 3.0.0 |
(2021) RogueFlashVue
Single-page application.

| Bulma | 0.9.2 |
| Jest | 24.9.0 |
| PouchDB | 7.2.2 |
| Visual Studio Code | 1.56.2 |
| Vue Router | 4.0.0 |
| Vue.js | 3.0.0 |
(2021) RogueFlashNg
Single-page application.

| Angular | 11.0.9 |
| Angular Flex-Layout | 11.0.0-beta.33 |
| Angular Material | 11.2.2 |
| Dexie | 3.0.3 |
| Jasmine | 3.6.0 |
| Karma | 5.1.0 |
| Protractor | 7.0.0 |
| RxJS | 6.6.0 |
| TypeScript | 4.1.5 |
| Visual Studio Code (VSCodium) | 1.53.2 |
(2019) RogueFlashSPJO
RESTful(ish) service.
| Eclipse | 2019-03 (4.11.0) |
| Java | JDK 8u192 |
| jOOQ | 3.11.11 |
| PostgreSQL | 11.0.3 |
| Project Lombok | 1.18.8 |
| Spring Batch | 4.1.2.RELEASE |
| Spring Boot | 2.1.5.RELEASE |
| Spring Framework | 5.1.7.RELEASE |
| Spring Web Service | 3.0.7.RELEASE |
(2018) RogueFlashJspSP
Web application. Port of RogueFlashJspHB to Spring, same db.

| Apache Tomcat | 9.0.12 |
| Eclipse | 2018-09 (4.9.0) |
| Hibernate | 5.3.7.Final |
| HTML | 5 |
| Java | JDK 8u192 |
| JPA | 2.2 |
| jQuery | 3.3.1 |
| JSP | 2.3 |
| MapStruct | 1.2.0.Final |
| PostgreSQL | 11.0.0 |
| Selenium Java | 3.141.0 |
| Servlet | 4.0 |
| Spring Data JPA | 2.1.2.RELEASE |
| Spring Framework | 5.1.2.RELEASE |
(2017) RogueFlashNetCoreMvc
Web application. Port of RogueFlashJspHB to ASP.NET Core, same db.
| ASP.NET Core | 1.1 |
| C# | .NET Core 1.0.1 |
| Entity Framework Core | 1.1 |
| HTML | 5 |
| jQuery | 3.1.1 |
| PostgreSQL | 9.5.3 |
| Selenium WebDriver | 3.3.0 |
| Visual Studio | Community 2015 (14.0.25431.01 Update 3) |
(2017) RogueFlashJspEL
Web application. Port of RogueFlashJspHB to GlassFish and EclipseLink.
Differences only.| EclipseLink | 2.6.1 |
| GlassFish | Open Source Edition 4.1.1 |
(2017) RogueFlashJspHB
Web application.
| Apache Tomcat | 8.0.36 |
| Eclipse | Mars Release (4.5.0) |
| Hibernate | 5.2.1 |
| HTML | 5 |
| Java | JDK 8u51 |
| JPA | 2.1 |
| jQuery | 3.1.1 |
| JSP | 2.3 |
| PostgreSQL | 9.5.3 |
| Servlet | 3.0 |
In this tutorial we will see how to call a C++ library from a Mono for Android app. Out of sheer curiosity and in the face of pragmatism, instead of resorting to P/Invoke we will make use of Cxxi, a framework that is still in development and aims to improve the interoperability between C++ and Mono.
Native library
The native library that we are going to use is Boost.Geometry and, as in the past, we will limit ourselves only to boolean operations on polygons. This choice leads to difficulties due to the heavy use of templates in the library so, in order to export the features that we need, we will use the following class (which is inspired by KBool):
//
// Wrapper.h
//
#if defined(_MSC_VER)
#define EXPORT __declspec(dllexport)
#else
#define EXPORT
#endif
namespace ClippingLibrary
{
class EXPORT Wrapper
{
public:
Wrapper();
~Wrapper();
void AddInnerRing();
void AddOuterRing();
void AddPoint(double x, double y);
void ExecuteDifference();
void ExecuteIntersection();
void ExecuteUnion();
void ExecuteXor();
bool GetInnerRing();
bool GetOuterRing();
bool GetPoint(double& x, double& y);
void InitializeClip();
void InitializeSubject();
private:
class Implementation;
Implementation* _pImpl;
};
}
In doing so the real and proper implementation of the library is completely hidden and Cxxi will have to deal only with class members that at the most expect two parameters of type double.
Moreover, to build the library for Android, it is necessary to modify the file
$BOOST_ROOT\boost\detail\endian.hpp
in this way:
#ifndef BOOST_DETAIL_ENDIAN_HPP
#define BOOST_DETAIL_ENDIAN_HPP
// GNU libc offers the helpful header <endian.h> which defines
// __BYTE_ORDER
#if defined (__GLIBC__) || defined(ANDROID)
# include <endian.h>
For further details about Boost on Android:
https://github.com/MysticTreeGames/Boost-for-Android
Ndk
Ndk (Native Developement Kit) is a set of tools that allow to build C and C++ libraries so that they can be used on Android. In particular, through Ndk we can carry out a cross-compilation. So, for example, a library built on Windows can be executed on an Android device.
First thing, it is necessary to prepare an Ndk project creating a main directory with any name and then a subdirectory that must be called jni. Then, inside the jni subdirectory, we create two new files that are required to configure the project.
The first file is Application.mk:
APP_STL := gnustl_static
APP_ABI := \
armeabi \
armeabi-v7a
- APP_STL, specifies the C++ runtime to be used.
Ndk provides several runtimes with different characteristics and licenses. Given that we have Boost as dependency, C++ exceptions support is required. At the moment, the only runtime that has such capability is Gnu Stl, which is under Gpl v3 license. Also, we use the static version since we want to create only one library.
- APP_ABI, specifies the hardware architecture on which our software will run.
If omitted the default value is armeabi.
The second file is Android.mk:
LOCAL_PATH := $(call my-dir) include $(CLEAR_VARS) LOCAL_MODULE := Native LOCAL_SRC_FILES := Wrapper.cpp LOCAL_CPPFLAGS += -fexceptions LOCAL_C_INCLUDES := W:\Boost include $(BUILD_SHARED_LIBRARY)
- LOCAL_PATH, specifies the path of the current Android.mk file and must be defined at the beginning. The macro $(call my-dir) returns the path to Android.mk itself.
- include $(CLEAR_VARS), resets various global variables and must be used in case the project is composed of several modules.
- LOCAL_MODULE, specifies the module name.
- LOCAL_SRC_FILES, lists the source files to be built. It must not contain header files.
Note that in this example, Wrapper.h and its implementation Wrapper.cpp must be inside the jni directory.
- LOCAL_CPPFLAGS, lists the flags to be passed to the C++ compiler.
fexceptions enables exceptions support, otherwise the following error should appear:
$BOOST_ROOT/boost/numeric/conversion/converter_policies.hpp:162: error: exception handling disabled, use -fexceptions to enable
- LOCAL_C_INCLUDES, lists the paths where headers of dependencies like Boost can be found.
- include $(BUILD_SHARED_LIBRARY), specifies that the output must be a shared library.
At this point, the PATH system variable must include the path to the Ndk installation directory. We can open a shell or command prompt and go to the main directory of our Ndk project and, finally, launch the following command:
ndk-build
At the end of the build process, inside the main directory of the project there should be a subdirectory named libs, and this should be its content:
libs
+---armeabi
| libNative.so
|
\---armeabi-v7a
libNative.so
For every architecture specified in the Application.mk file there is a subdirectory with its version of the library. Note that the name of the file is libNative.so, where Native is the name of the module specified in the Android.mk file and lib is a prefix added for convention.
For further details it is advisable to refer to the documentation provided with the Ndk, expecially the html files OVERVIEW, CPLUSPLUS-SUPPORT, APPLICATION-MK and ANDROID-MK.
Gcc-Xml
Gcc-Xml is a tool that parses C++ code and generates an xml file containing a description of the parsed code. Then, the xml file can be used by other tools that need access to the structure of the C++ code, avoiding to tackle directly the complex parsing phase.
The development version of Gcc-Xml is still being updated. The source code can be checked out from the git repository according to the instructions on the download page, and it is ready to be used with CMake.
Note that Gcc-Xml requires the presence of a C++ compiler, the PATH system variable must include the path to the compiler, and if you choose to download pre-built binaries you must be sure that they support such compiler.
Once obtained the binaries for Gcc-Xml, we can execute the following command:
gccxml --gccxml-compiler gcc -fxml=Wrapper.xml Wrapper.h
- gccxml-compiler, specifies the compiler to be used.
We opted for gcc but, for example, on Windows we could have used msvc10.
- fxml, sets the name of the xml file to be generated.
- Wrapper.h, in the end, is the name of the source file to be parsed.
Cxxi
Cxxi is a tool that enables the use of C++ libraries from managed code. In this regard, if you have not yet done so, it could be interesting to read this introduction that also lists some of the features that make Cxxi different from other solutions such as Swig:
CXXI: Bridging the C++ and C# worlds.
Here you can find the master branch:
However we are going to use this fork:
https://github.com/kthompson/cxxi
This is because some problems still present in the master have been solved in the fork, in particular with parameters passed by reference as in the GetPoint method seen in our Wrapper class.
The source code comes with a solution file (.sln) that can be opened with Visual Studio 2010 or MonoDevelop. As the result of the build process, we get two files:
- Generator.exe
- Mono.Cxxi.dll
But presently, in release mode, the name of the dll is CPPInterop.dll.
At this point we can feed Generator.exe with the xml file previously created by Gcc-Xml:
generator -abi=ItaniumAbi -ns=CxxiGeneratedNamespace -lib=Native -o=OutputFolder Wrapper.xml
- abi, specifies the abi used by our native library.
The abi used on Arm seems to be based on the Itanium abi and moreover Ndk uses gcc as compiler so the value of the abi option must be set to ItaniumAbi. If we were trying to use a library built with Visual C++ from a Windows application, we should specify MsvcAbi.
- ns, specifies the namespace that encloses the files created by Generator.exe
- lib, is the name of the native library without the lib prefix.
- o, is the directory where Generator.exe puts the output files.
- Wrapper.xml, in the end, is the name of the xml file generated by Gcc-Xml
The first file obtained in our example is Lib.cs:
using System;
using Mono.Cxxi;
using Mono.Cxxi.Abi;
namespace CxxiGeneratedNamespace {
public static partial class Libs {
public static readonly CppLibrary Native =
new CppLibrary ("Native",
ItaniumAbi.Instance,
InlineMethods.NotPresent);
}
}
The namespace is the same one specified in the previous command, and the name of the library and the choosen abi are passed to the CppLibrary constructor.
The second file is Wrapper.cs (slightly reformatted):
using System;
using Mono.Cxxi;
namespace CxxiGeneratedNamespace.ClippingLibrary {
public partial class Wrapper : ICppObject {
private static readonly IWrapper impl =
Libs.Native.GetClass<IWrapper,_Wrapper,Wrapper> (
"Wrapper");
public CppInstancePtr Native { get; protected set; }
public static bool operator!=(Wrapper a, Wrapper b)
{
return !(a == b);
}
public static bool operator==(Wrapper a, Wrapper b)
{
if (object.ReferenceEquals(a, b))
return true;
if ((object)a == null || (object)b == null)
return false;
return a.Native == b.Native;
}
public override bool Equals(object obj)
{
return (this == obj as Wrapper);
}
public override int GetHashCode()
{
return this.Native.GetHashCode();
}
[MangleAs ("class ClippingLibrary::Wrapper")]
public partial interface IWrapper :
ICppClassOverridable<Wrapper>
{
[Constructor] CppInstancePtr Wrapper (
CppInstancePtr @this);
[Destructor] void Destruct (CppInstancePtr @this);
void AddInnerRing (CppInstancePtr @this);
void AddOuterRing (CppInstancePtr @this);
void AddPoint (CppInstancePtr @this,
double x, double y);
void ExecuteDifference (CppInstancePtr @this);
void ExecuteIntersection (CppInstancePtr @this);
void ExecuteUnion (CppInstancePtr @this);
void ExecuteXor (CppInstancePtr @this);
bool GetInnerRing (CppInstancePtr @this);
bool GetOuterRing (CppInstancePtr @this);
bool GetPoint (CppInstancePtr @this,
[MangleAs ("double &")] ref double x,
[MangleAs ("double &")] ref double y);
void InitializeClip (CppInstancePtr @this);
void InitializeSubject (CppInstancePtr @this);
}
public unsafe struct _Wrapper {
public IntPtr _pImpl;
}
public Wrapper (CppTypeInfo subClass)
{
__cxxi_LayoutClass ();
subClass.AddBase (impl.TypeInfo);
}
public Wrapper (CppInstancePtr native)
{
__cxxi_LayoutClass ();
Native = native;
}
public Wrapper ()
{
__cxxi_LayoutClass ();
Native = impl.Wrapper (impl.Alloc (this));
}
public void AddInnerRing ()
{
impl.AddInnerRing (Native);
}
public void AddOuterRing ()
{
impl.AddOuterRing (Native);
}
public void AddPoint (double x, double y)
{
impl.AddPoint (Native, x, y);
}
public void ExecuteDifference ()
{
impl.ExecuteDifference (Native);
}
public void ExecuteIntersection ()
{
impl.ExecuteIntersection (Native);
}
public void ExecuteUnion ()
{
impl.ExecuteUnion (Native);
}
public void ExecuteXor ()
{
impl.ExecuteXor (Native);
}
public bool GetInnerRing ()
{
return impl.GetInnerRing (Native);
}
public bool GetOuterRing ()
{
return impl.GetOuterRing (Native);
}
public bool GetPoint (ref double x, ref double y)
{
return impl.GetPoint (Native, ref x, ref y);
}
public void InitializeClip ()
{
impl.InitializeClip (Native);
}
public void InitializeSubject ()
{
impl.InitializeSubject (Native);
}
partial void BeforeDestruct ();
partial void AfterDestruct ();
public virtual void Dispose ()
{
BeforeDestruct ();
impl.Destruct (Native);
Native.Dispose ();
AfterDestruct ();
}
private void __cxxi_LayoutClass ()
{
impl.TypeInfo.CompleteType ();
}
}
}
Here, again, we can note the namespace to which has been added ClippingLibrary, the namespace of the native library. Furthermore, the class takes the name of the respective native class, Wrapper. If there were more classes, there would be a file for each class.
Mono for Android
Through Mono for Android, C# developers can write apps for Android without the need to learn Java. The trial version has no time limits but only allows to deploy to the Android emulator. The installer downloads all the necessary, Android Sdk and MonoDevelop included.
To test our library we can execute the following steps (the description refers to MonoDevelop but the steps for Visual Studio are similar):
- Create a new Solution called TestMonoDroid. Select a Mono for Android project type (actually only available under C#).
- Add a new project to the solution and name it Cxxi. Select a Mono for Android Library Project type (only available under C#).
We can't use the previously created Mono.Cxxi.dll, the project must be rebuilt to target Mono for Android.
- Inside the Cxxi project add the same files found in the Mono.Cxxi project, in the original Mono.Cxxi source code.
- Under Project Options, Build, General, check Allow 'unsafe' code.
- Inside the TestMonoDroid project add a reference to the Cxxi project.
- Add the files Lib.cs and Wrapper.cs, previously obtained with Generator.exe, to TestMonoDroid.
- Add the libs folder, previously obtained with Ndk, to TestMonoDroid.
- For every libNative.so file go to Properties, Build, and set Build action to AndroidNativeLibrary.
- Modify Activity1.cs and add code for testing the library (see below for an example).
- Build All.
- From the Run menu, select Upload to Device.
- Start an emulator and once the upload is done launch the TestMonoDroid app.
Some problems could arise in this phase, in that case these resources may be of help:
MonoDroid: Not connecting to Emulator
MonoDroid: Running out of space on fresh Virtual Device?
Unsupported configuration: ... armeabi-v7a-emu.so in Mono for Android v4.0
This is an example of how to use the library:
// ...
using CxxiGeneratedNamespace.ClippingLibrary;
// ...
private static string RunTest()
{
var w = new Wrapper();
w.InitializeSubject();
w.AddOuterRing();
w.AddPoint(0, 0);
w.AddPoint(0, 1000);
w.AddPoint(1000, 1000);
w.AddPoint(1000, 0);
w.AddPoint(0, 0);
w.AddInnerRing();
w.AddPoint(100, 100);
w.AddPoint(900, 100);
w.AddPoint(900, 200);
w.AddPoint(100, 200);
w.AddPoint(100, 100);
w.AddInnerRing();
w.AddPoint(100, 700);
w.AddPoint(900, 700);
w.AddPoint(900, 900);
w.AddPoint(100, 900);
w.AddPoint(100, 700);
w.InitializeClip();
w.AddOuterRing();
w.AddPoint(-20, 400);
w.AddPoint(-20, 600);
w.AddPoint(1020, 600);
w.AddPoint(1020, 400);
w.AddPoint(-20, 400);
w.AddInnerRing();
w.AddPoint(100, 450);
w.AddPoint(900, 450);
w.AddPoint(900, 550);
w.AddPoint(100, 550);
w.AddPoint(100, 450);
w.ExecuteDifference();
return GetOutputString(w);
}
// ...
Note that rings must be closed and outer rings must be clockwise while inner rings must be anti-clockwise.
Not very choreographic but it runs!

Conclusion
We have seen how to use a native library from a MonoDroid app. A more pragmatic approach would have excluded Cxxi in favour of a more mature solution (and in this specific case we could have avoided a lot of issues by using the C# version of Clipper). However Cxxi is an interesting project that can offer more than what we have seen here, and in the future it could become the standard solution for interoperability between C++ code and Mono so keep an eye on it.
Download
Support files (also contains Wrapper.h and Wrapper.cpp).
Notes
Tested with:- Android 3.1 (Emulated)
- Android Ndk r7b
- Boost 1.49.0
- Cxxi kthompson-cxxi-1a9c3a8
- GCC_XML cvs revision 1.135
- Mono for Android 4.0.4.264524889 (Evaluation)
- MonoDevelop 3.0.1
